In everyday talk, people often use the words "likelihood" and "probability" as if they mean the same thing. You might say there's a high probability of rain or a strong likelihood of missing the train if you don’t leave soon. In casual use, they’re interchangeable. But in the world of statistics and AI, they aren’t.
These two words carry distinct meanings and are used in different contexts for different purposes. This difference matters, especially when building models, making predictions, or interpreting data. Understanding how they diverge clears up confusion and improves how we work with uncertainty in data-driven tasks.
Defining Probability and Its Role in Modeling
Probability deals with predicting future outcomes based on a known model. It's a forward-looking tool that helps us answer questions like, “What is the chance of flipping a coin and getting heads?” or “What’s the chance that this email is spam?” In this setting, we already know the parameters or assumptions — like the fairness of a coin — and we're using those to estimate the likelihood of possible outcomes.
In a technical sense, probability measures the chance that an outcome will occur, given certain parameters. In the context of machine learning or statistical modeling, probability typically shows up when we're trying to model the outcome of an event based on a set of given conditions. For example, if we know that 70% of emails with certain keywords are spam, we can say there's a 0.7 probability that a new email with those words is spam.
Probability is fundamental to generative models, which try to simulate data that looks like the real thing. Think of a model generating realistic handwriting or faces — these models rely heavily on known probabilities to produce new, synthetic samples. They begin with assumptions about how data behaves and use those to predict what might happen next.
Understanding Likelihood in Inference
Now, flip the idea of probability around. Suppose you’re given some actual observed data, and instead of predicting outcomes, you're trying to figure out which parameters most likely produced that data. That’s where likelihood comes in.

Likelihood is a function of the parameters given the observed data. You're not asking, "What is the chance of this data happening if the parameters are known?" (that's a probability), but rather, "Given this data, which parameters make this data most plausible?" This subtle change shifts the entire approach.
This concept is the heart of parameter estimation. In AI and statistics, a common task is to tune model parameters so that the model best fits the data. This is done through likelihood functions. The model that assigns the highest likelihood to the observed data, given different candidate parameters, is chosen as the best one.
For instance, in natural language processing, if you want your model to guess the most probable word sequence, you train it on the existing text and adjust the model's parameters using maximum likelihood estimation (MLE). The goal is to find the parameter values that make the training data most likely under the model.
In essence, while probability works from parameters to data, likelihood works from data to parameters.
Practical Impact on AI Systems
At first glance, this difference might seem abstract. But it has real consequences in AI, especially in how models are built and trained.
Say you're working on a classification problem — like identifying whether an image shows a dog or a cat. Probability is involved when the trained model estimates a 90% chance that a photo is a dog. However, during training, when the model is still learning to recognize what makes an image a dog or a cat, it adjusts its parameters to maximize how well it matches the training data. That's a likelihood in action.
One practical example is in Bayesian inference, where the line between probability and likelihood becomes central. In Bayesian thinking, the prior probability represents what we believe before seeing any data. The likelihood updates that belief based on the observed data. The final product — the posterior probability — combines both. Without keeping the roles of likelihood and probability clear, this process would break down.
In neural networks and deep learning, the loss functions used for classification tasks often involve the negative log-likelihood. This means the model is being trained to increase the likelihood of the correct output label, working backward from observed data to parameter values.
This is also important in generative AI. When models are trained on large datasets — such as text, images, or audio — they rely on the likelihood to learn how the data is distributed. Once trained, they can then use probability to generate new content, such as text completions or image synthesis. Mixing up the two would lead to misunderstandings in both training and generation.
Key Differences at a Glance — Without Redundancy
To make the contrast clear without repeating the same points, probability is about forecasting; likelihood is about backtracking. Probability is used when the model is fixed and you're looking ahead to possible outcomes. Likelihood is used when the outcomes are fixed (observed data) and you're adjusting the model.
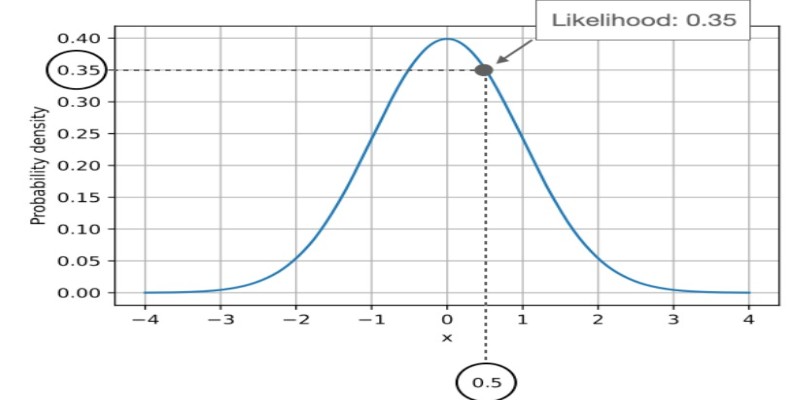
Their mathematical expressions differ as well. Probability is often written as P(data | parameters), and likelihood is L(parameters | data). While they may appear similar, their focus and use cases are not.
In AI, where decisions are data-driven and models are only as good as their training process, clarity on this distinction can significantly impact accuracy, interpretability, and performance.
Both terms describe uncertainty. But they do it in opposite directions — and knowing which tool you’re using helps keep your reasoning straight when designing or interpreting machine learning models.
Conclusion
Likelihood and probability often walk side by side, but they’re not twins. They're more like two tools in the same box, each used for different jobs. One helps you look ahead, and the other helps you look backward. One predicts, and the other interprets. Confusing them won’t always lead to disaster, but for anyone working with models, especially in AI and data science, that confusion can muddy results and skew understanding. Getting the difference right isn’t about being pedantic; it’s about building models that actually work the way you expect. And that makes all the difference in producing trustworthy, explainable systems that people can rely on.











